
How AI can enhance your resource modeling

This past year saw lightning-fast advancements in generating artificial intelligence (AI). It’s clear that AI is quickly becoming integrated into daily life around the globe. Maybe you already drive an AI-powered car or use ChatGPT for research or writing, but did you know that AI — and more specifically machine learning (ML) — is also a powerful tool for resource modeling?
Machine learning is a branch of AI that uses data and algorithms to learn the way humans learn: by doing a task over and over and using our experience of doing that task to become better at it.
To put it another way, ML enables computers to learn data patterns and trends without being explicitly programmed to do so. The computer then uses these data patterns to approximate the existence of an underlying process or model. It does this using supervised and/or unsupervised learning algorithms.
Background: Supervised/unsupervised machine learning
With supervised learning, the machine learns from labelled data (data with known input and output pairs). From the relationship between input and output data, the algorithm generates a function capable of making predictions for future input data. The aim is to find the optimum parameters for the model by minimising the difference between predicted and actual output. Spam filters are examples of internet service providers using supervised learning to identify spam accurately.
In unsupervised learning, labelled data is not required because here the aim is not to make predictions but rather to use input data to reveal pattern groups — to recognise the inherent structure of the data and make correlations between data. The movie and TV recommendations Netflix sends out to individual subscribers are examples of this type of ML based on their previous viewing choices.
Whether a task uses one or both learning algorithms depends on the available data and the specific task at hand. Algorithms can also be combined and complement each other to identify patterns in diverse datasets originating from a broad range of sources, enabling the interpretation of extensive datasets with remarkable efficiency.
It's important to note, however, that while ML models can process vast amounts of data quickly, their accuracy is dependent on the quality of the data and the effectiveness of the chosen algorithms.
Machine learning and resource modeling
Throughout the lifecycle of a mine from discovery, evaluation, production, through to distribution and rehabilitation, resource modeling stands out as a key component, especially during those three crucial initial phases. This is when the most accurate modeling possible is required to underpin critical decisions that will have an impact on the entire mining process.
To develop a resource model, a geologist must first gather the full spectrum of available geoscience data from a diversity of datasets, including government geological records, topographical maps, field reports, borehole samples, satellite imagery, magnetic field readings, and more. Using this data, the geologist then creates a comprehensive model for lithology that allows for the separation of data into estimation domains. After that, the model interpolates grades or other variables of interest in a block model. The block model then becomes a foundational tool for mine planning schedules during the exploitation phase.
Sounds almost easy, doesn’t it? But in reality, resource modeling presents a number of challenges for a geologist, including dealing with large and complex datasets, the need to invest substantial amounts of time and money in sample collection and testing, and accounting for multiple uncertainties in the modeling process.
With assistance from AI, however, the geologist can use ML to
- recognise patterns within vast oceans of data
- use those patterns to develop a process that automatically predicts variables of interest and quantifies potential risks.
Case study 1: Machine learning in domain separation
A critical process in resource modeling, particularly when working with a geometrically complex ore body, involves delineating distinct estimation domains tailored to the unique characteristics of a deposit. To do this, the geologist separates the domains based on a comprehensive analysis of sample data and applies various estimation parameters to ensure that each domain displays spatial continuity and conforms to a singular, stationary statistical model.
We devised a test case for a porphyry-skarn deposit (copper, gold, silver, etc) in Peru to illustrate how ML can work in domain separation. The datasets consisted of 32,711 composites comprising 35 variables derived from 273 drill holes, including minerals grade, lithology, alteration, and various geochemical factors.
The main challenge for estimation at this mine was the potential for economic loss caused by improper domain, which could lead to underestimating high-grade minerals. To address this challenge, we employed a clustering algorithm. This algorithm incorporated the geostatistical Mahalanobis distance function instead of Euclidean distance, which meant that it not only considered variograms of key properties, it also factored-in cross variograms among copper, gold, silver and geochemical variables.
Figure 1 shows the results of applying this approach: four separate domains, each represented by a different colour.
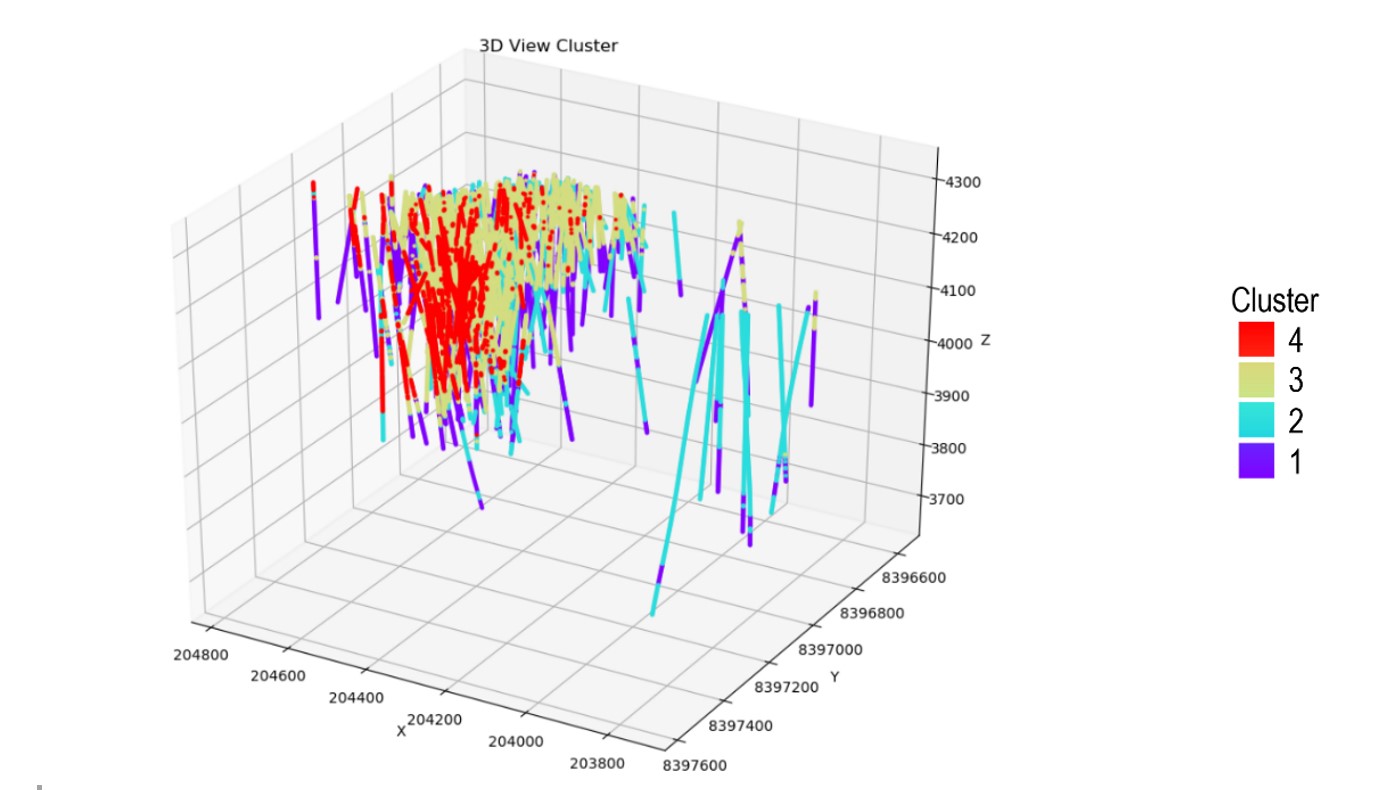
Figure 1. Display of clusters of copper domain considering coordinates, drillhole data of all variables, and lithology.
Note that, unlike traditional domaining methods, this approach identified some transition layers (part of domain 4 in domain 3) within the skarn (domain 3 and domain 4). You can also see here that, by recognising the pattern and relation between geochemical properties and copper grade, the ML model effectively pinpointed the high-grade zone and generated a clear boundary between domain 3 and domain 4.
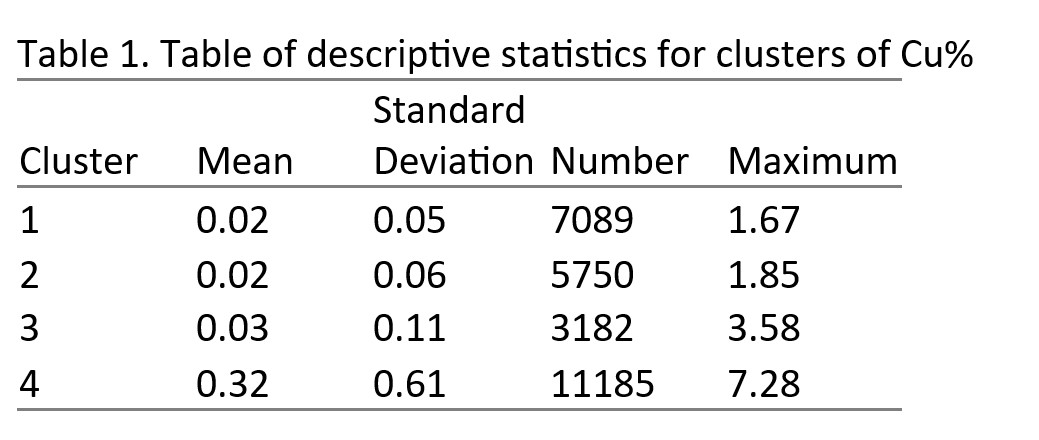
In Table 1, cluster 4 stands out statistically due to its high-average sample grade (0.32) and its maximum sample grade (7.28).
To validate the relevance of the four clusters and identify if there was any redundancy among the domains, we conducted a principal component analysis in two dimensions representing combinations of geochemical properties.
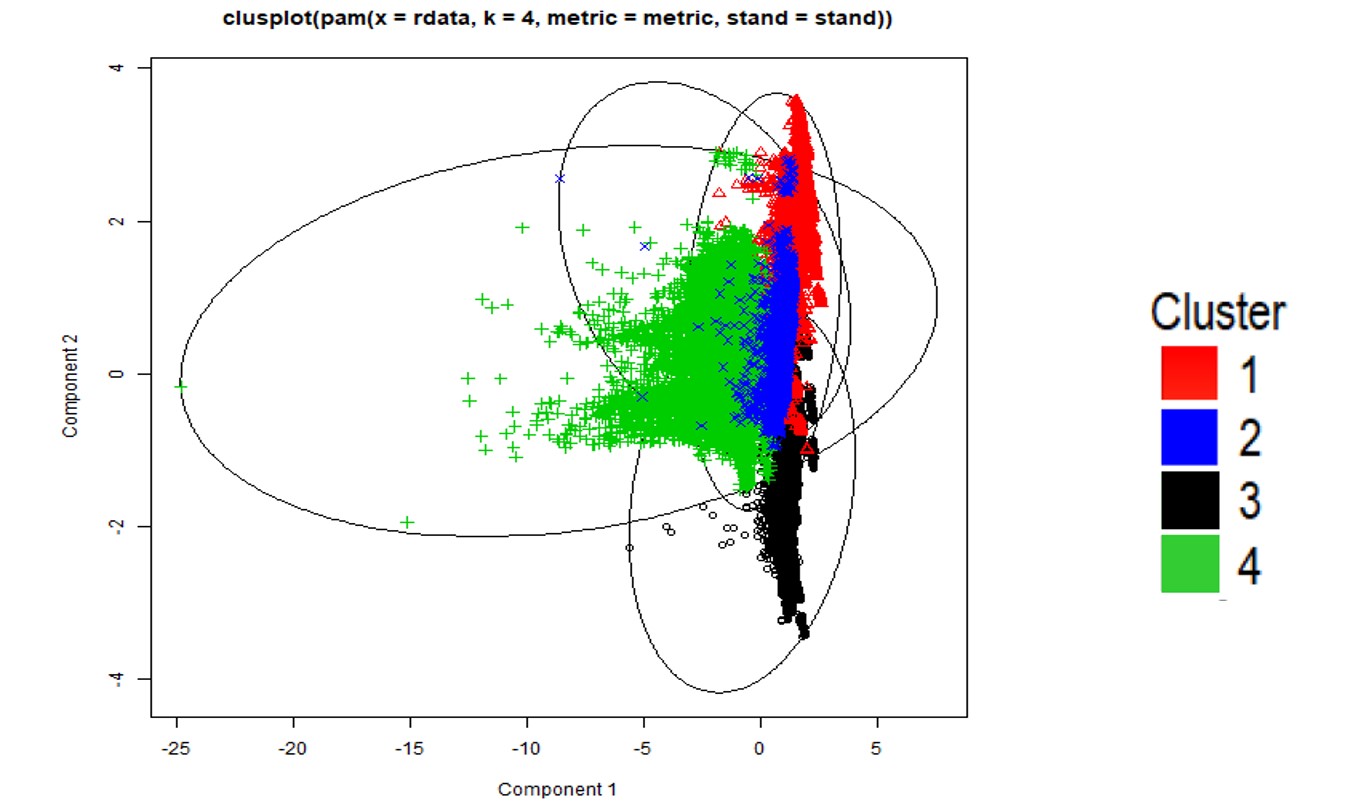
Figure 2. Principle component analysis score of two components from datasets.
The result was that, by increasing confidence in identifying domains, we were able to integrate up to one per cent more economic grade into the main lithology domain. In addition, this streamlined process took mere minutes from start to finish, instead of the weeks required for traditional domaining.
Case 2: Machine learning to reduce core hole drilling
Core hole drilling carried out during the exploration and production phases yields essential information for resource estimation, but it is very expensive and lab analytical results take a long time to obtain. And while non-core holes are more cost-effective and efficient, they cannot provide quality samples for certain minerals.
In response to these challenges, we decided both to explore the potential of leveraging geophysical data to enhance the precision of the spatial quality model, and to evaluate whether a significant enhancement in estimation precision could lead to a reduction in the need for core hole drilling, thereby minimizing exploration expenses.
In this case study, we used datasets from five mines along the Sydney-Gunnedah-Bowen Basin in Australia, including quality samples (ash, volatile matter, relative density, and fixed carbon) from core holes, and geophysical measurements (gamma, bulk density, and electrical resistance) from all drillholes. The number of geophysical samples were, depending on the sites, 5 to 10 times greater than the number of quality samples.
For the geology and in-situ resource prediction, we employed four ML models: random forest, generalized linear, gradient boosting machine, and deep learning. To determine the optimal model, we cross-validated each model and created a stacked ensemble model. We obtained the lithology layer and quality predictions in non-core holes by recognizing the patterns and relationships between the geophysical information, the lithology, and quality.
For the resource modeling phase, our dataset included quality assays from core holes and ML predictions in non-core holes, known as ‘pseudo samples’ because they were not directly collected from drillholes. We also adapted the inverse-distance weighting method to incorporate samples from multiple sources, and compared estimations across three scenarios: exclusively using core samples (which we used as our baseline); using all core samples and pseudo samples; and incorporating varying percentages of core samples alongside all pseudo samples.
The results:
- In lithology prediction, the accuracy of ore boundary identification exceeded 98%, but the accuracy for clastic lithofacies varied between 80% and 90%, potentially influenced by inconsistencies in the geology logs. However, a comprehensive evaluation, using a confusion matrix and encompassing 155 thousand tests across 37 lithology layers, revealed an impressive overall accuracy of 97%, indicating a high level of precision in the predictions.
- Predictions for ash content, volatile matter, relative density, and fixed carbon varied across sites, influenced by factors such as data quality, the quantity of labeled data, and the spatial location of drill holes. Across five sites, the Mean Absolute Error (MAE) for coal quality consistently registered below 10%, and the coefficient R2 consistently exceeded 0.9.
- Figure 3, below, depicts the percentage of drillhole removal for our baseline resource modeling scenario (using only core samples). At the starting point, with no core holes dropped, you can see that using all assay data and pseudo samples in estimation resulted in a lower MAE than the base case. And for ash content and relative density specifically, our case study showed that a reduction in core hole drilling of approximately 20% (59 holes removed out of 297 core holes) and 28% (83 holes removed out of 296 core holes) respectively could be achieved while maintaining the same MAE as the base case.
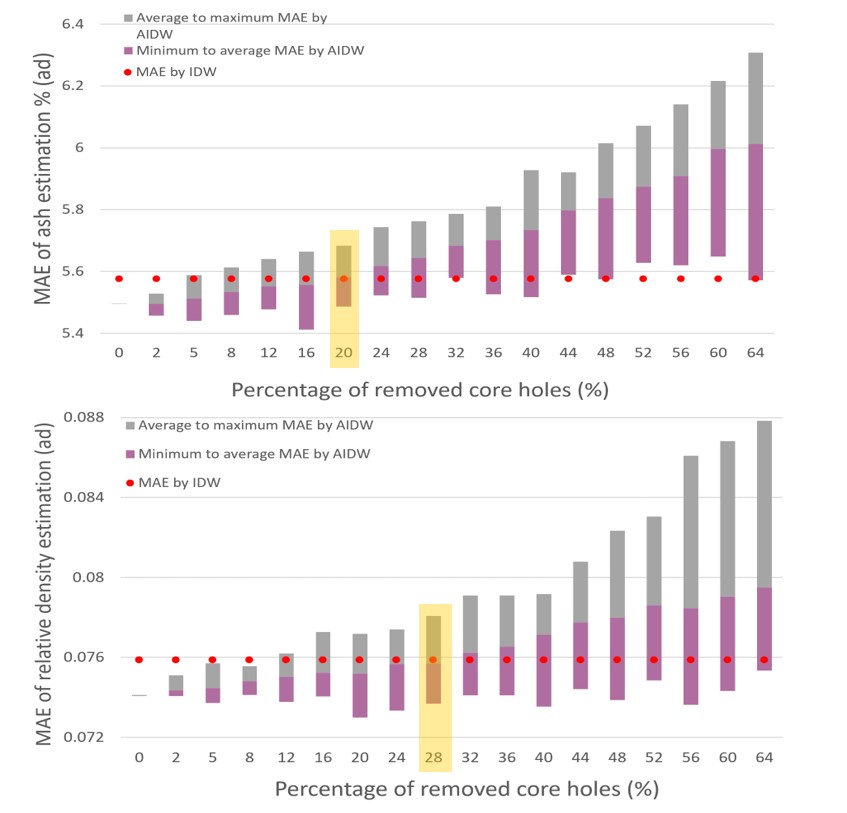
Figure 3. MAE of ash (top) and relative density (bottom) estimation with percentage of core hole reduction.The red dots represent a base case that only uses the core hole data. For each reduction percentage, we ran 100 cases with random dropping pattern. This bar covers the range of MAE. And the boundary of two colors is the mean MAE.
Conclusion
Machine learning can handle complex, multi-variate datasets by recognizing intricate patterns that may evade human observation. By uncovering inherent variations in geological data, it also allows for a better reflection of subsurface reality, while its ability to rapidly process vast datasets and automate repetitive tasks can not only streamline workflows but also empower faster, better-informed decisions.
In addition, by enabling increased concentration on the spatial features of geoscience variables, the collaboration between ML and geostatistics can lead to more confident and reliable resource estimations, while ML’s capacity to generate pseudo samples for mineral grade in areas with limited core hole data can lessen the reliance on core hole drilling, which will not only improve the model’s confidence but also contribute to the efficient management of drilling costs.
At the same time, however, because resource estimation affects both upstream and downstream processes over a mine’s entire lifetime, it’s vital to approach ML applications in resource estimation with caution. Even with ML’s advanced capabilities, geologists with strong domain expertise are still required to validate results. But if we can keep industry knowledge and experience at the forefront while adding cutting-edge technology like ML, we believe the mining sector will be able to enter into a new era of increased efficiency and accuracy.
Please note: Bulletin articles are general in nature and not peer reviewed.
Find out more
If you’re interested to learn more, we invite readers to join the GEOVIA User Community by Dassault Systèmes, to read about industry topics from experts. All industry professionals are welcome to learn, engage, discover, and share knowledge to shape a sustainable future of mining.